# Data Ingestion with Apache Kafka
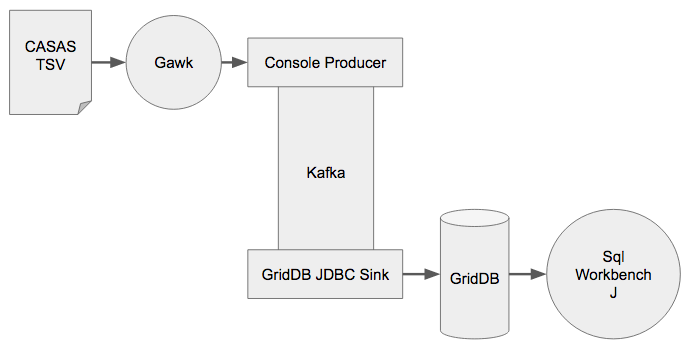
In this tutorial we feed the CASAS Dataset through Kafka and into GridDB with Confluents kafka-connect-jdbc. The raw TSV data will be converted into JSON with Gawk and then fed into Kafka with a Console Producer. Then kafka-connect-jdbc will write the data to GridDB without writing any code. Finally, we'll inspect the data with SQLWorkbench/J.
# Setup Kafka
Kafka (opens new window) is a data streaming platform with many different possible inputs and outputs that are easy to create. For this tutorial we'll use a Kafka Console Producer to put data into Kafka which will be then consumed by Kafka Connect Sink that we are going write. We are going to follow the Kafka Quickstart (opens new window). Kafka can be downloaded from their downloads page (opens new window), we're using version 2.12-2.5.0. You will also need to have a Java 1.8 development environment installed on your system. After downloading, we simply untar and start the Zookeeper and Kafka Servers.
$ tar xzvf kafka_2.12-2.5.0.tgz
$ cd kafka_2.12-2.5.0
$ export PATH=$PATH:/path/to/kafka_2.12-2.5.0/bin
$ zookeeper-server-start.sh --daemon config/zookeeper.properties
$ kafka-server-start.sh --daemon config/server.properties
# Running the GridDB Sink
We will assume that you already have GridDB 4.5 CE installed and have the latest the GridDB JDBC Jar built. We will copy GridDB JDBC jar and the Kafka Connect JDBC Jar to the Kafka Libs folder. The Kafka Connect JDBC Jar can be downloaded from here (opens new window) and the source can be fetched from GitHub (opens new window).
The GridDB JDBC connector had to be modified for use with kafka-connect-jdbc, it can be downloaded from here (opens new window) and the source can be viewed here (opens new window).
$ cp /path/to/kafka-connect-jdbc/target/kafka-connect-jdbc-$VERSION-SNAPSHOT.jar /path/to/kafka_2.12-2.5.0/libs
$ cp /path/to/griddb-jdbc/bin/griddb-jdbc.jar /path/to/kafka_2.12-2.5.0/libs
A configuration file, configs/connect-jdbc.properties is required for Kafka Connect which defines the parameters for the JDBC sink, the topics it subscribes too, as well as a transform that converts datetime string into an object that can be written to the database.
bootstrap.servers=localhost:9092
name=griddb-sink
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
tasks.max=1
key.converter.schemas.enable=true
value.converter.schemas.enable=true
batch.size=1
topics.regex=csh(.*)
connection.url=jdbc:gs://239.0.0.1:41999/defaultCluster/public
connection.user=admin
connection.password=admin
auto.create=true
transforms=TimestampConverter
transforms.TimestampConverter.type=org.apache.kafka.connect.transforms.TimestampConverter$Value
transforms.TimestampConverter.format=yyyy-MM-dd hh:mm:ss
transforms.TimestampConverter.field=datetime
transforms.TimestampConverter.target.type=Timestamp
Now we can start Kafka Connect:
$ cd path/to/kafka
$ ./bin/connect-standalone.sh config/connect-standalone.properties config/connect-jdbc.properties
# Data Set
CASAS (opens new window) is research group based out of the Washington State University that has a large sensor dataset (opens new window). The data was collected from a variety of in-home sensors while volunteers performed their normal daily routines. We are going to use this dataset in a series of tutorials to demonstrate how to use GridDB to ingest, analyze, and visualize data. The data looks like this:
2012-07-18 12:54:45.126257 D001 Ignore Ignore CLOSE Control4-Door
2012-07-18 12:54:45.196564 D002 OutsideDoor FrontDoor OPEN Control4-Door
2012-07-18 12:54:45.247825 T102 Ignore FrontDoorTemp 78 Control4-Temperature
2012-07-18 12:54:45.302398 BATP102 Ignore Ignore 85 Control4-BatteryPercent
2012-07-18 12:54:45.399416 T103 Ignore BathroomTemp 25 Control4-Temperature
2012-07-18 12:54:45.472391 BATP103 Ignore Ignore 82 Control4-BatteryPercent
2012-07-18 12:54:45.606580 T101 Ignore Ignore 31 Control4-Temperature
2012-07-18 12:54:45.682577 MA016 Kitchen Kitchen OFF Control4-MotionArea
2012-07-18 12:54:45.723461 D003 Bathroom BathroomDoor OPEN Control4-Door
2012-07-18 12:54:45.767498 M009 Bedroom Bedroom ON Control4-Motion
We've also made a smaller subset of the data available here (opens new window) in case you do not wish to download the entire 13GB original zipfile.
The fields of the TSV file are:
- Date
- Time
- Sensor ID
- The Room the sensor is in.
- What the sensor is sensing
- Sensor Message
- Sensor Activity
# Ingesting the Data
We will need to convert the TSV data into the schema expected by Kafka. To do so, we'll use a small shell-script:
#!/bin/bash
function echo_payload {
echo '{ "payload": { "datetime": "'$1 $2'", "sensor": "'$3'", "translate01": "'$4'", "translate02": "'$5'", "message": "'$6'", "sensoractivity": "'$7'" }, "schema": { "fields": [ { "field": "datetime", "optional": false, "type": "string" }, { "field": "sensor", "optional": false, "type": "string" }, { "field": "translate01", "optional": false, "type": "string" }, { "field": "translate02", "optional": false, "type": "string" }, { "field": "message", "optional": false, "type": "string" }, { "field": "sensoractivity", "optional": false, "type": "string" } ], "name": "ksql.users", "optional": false, "type": "struct" }}'
}
TOPICS=()
for file in `find $1 -name \*.rawdata.txt` ; do
echo $file
LOCATION=`echo $file | sed -e s/.rawdata.txt// -e s:.*/::g`
head -10 $file |while read -r line ; do
SENSOR=`echo ${line} | awk '{ print $3 }'`
if [[ ! " ${TOPICS[@]} " =~ " ${LOCATION}_${SENSOR} " ]]; then
echo Creating topic ${LOCATION}_${SENSOR}
kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic ${LOCATION}_${SENSOR} 2&>1 /dev/null
TOPICS+=(${LOCATION}_${SENSOR})
fi
echo_payload ${line} | kafka-console-producer.sh --topic ${LOCATION}_${SENSOR} --bootstrap-server localhost:9092
done
done
It will find any of the CASAS data files in the given path, create the Kafka topics and then input the data into Kafka via Kafka Console Producer.
If everything is working as it should, the Kafka Connect should output log entries like so:
[2020-12-14 18:52:37,786] INFO WorkerSinkTask{id=griddb-sink-0} Committing offsets asynchronously using sequence number 1:
{csh101_MA016-0=OffsetAndMetadata{offset=5, leaderEpoch=null, metadata=''}, csh102_LS013-0=OffsetAndMetadata{offset=4,
leaderEpoch=null, metadata=''}, csh101_D001-0=OffsetAndMetadata{offset=14, leaderEpoch=null, metadata=''},
csh101_D002-0=OffsetAndMetadata{offset=6, leaderEpoch=null, metadata=''}, csh101_D003-0=OffsetAndMetadata{offset=5,
leaderEpoch=null, metadata=''}, csh101_M009-0=OffsetAndMetadata{offset=5, leaderEpoch=null, metadata=''},
csh101_-0=OffsetAndMetadata{offset=26, leaderEpoch=null, metadata=''}, csh102_MA020-0=OffsetAndMetadata{offset=4, leaderEpoch=null, metadata=''}, csh102_-0=OffsetAndMetadata{offset=10,
leaderEpoch=null, metadata=''}, csh102_M021-0=OffsetAndMetadata{offset=12, leaderEpoch=null, metadata=''},
csh101_T103-0=OffsetAndMetadata{offset=6, leaderEpoch=null, metadata=''}, csh101_T102-0=OffsetAndMetadata{offset=6,
leaderEpoch=null, metadata=''}, csh101_T101-0=OffsetAndMetadata{offset=5, leaderEpoch=null, metadata=''},
csh101_BATP103-0=OffsetAndMetadata{offset=5, leaderEpoch=null, metadata=''}, csh101_BATP102-0=OffsetAndMetadata{offset=6,
leaderEpoch=null, metadata=''}} (org.apache.kafka.connect.runtime.WorkerSinkTask:349)
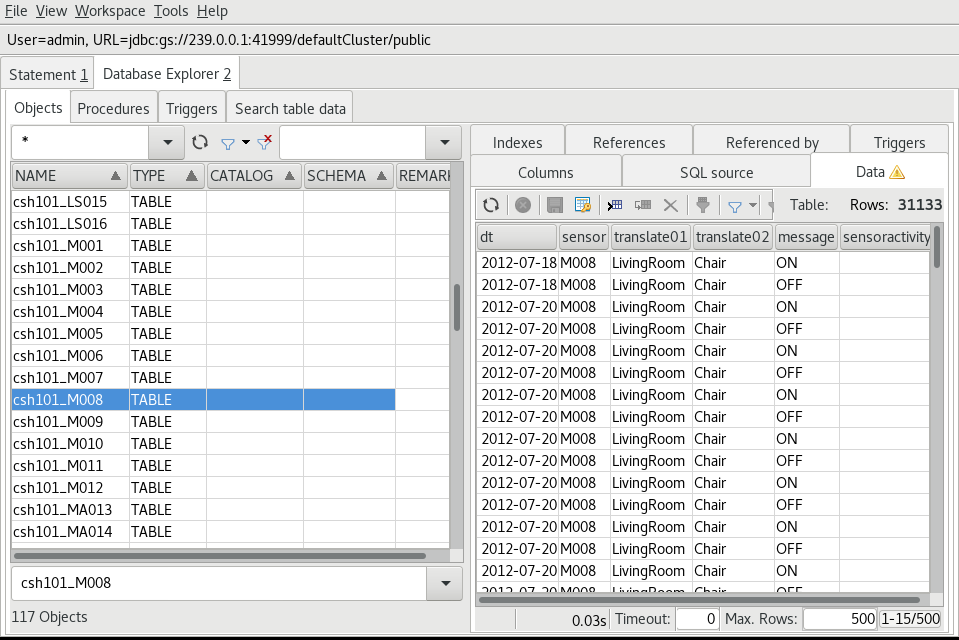
# Inspecting the Data
In a previous blog
post (opens new window),
we showed how to use SQLWorkbench/J to see data in GridDB so we're going
to use it here to have a look at the data. After a successful connection
to the database, select the Tools->Show Database Explorer menu item or
press Ctrl-d and a list of tables in GridDB will be shown. Selecting a
table will allow you to see it's data by selecting the Data tab on the
right as shown here.